You are not logged in.
- Topics: Active | Unanswered
#1 2024-03-22 22:31:12
- armandleg
- Member
- Registered: 2024-03-22
- Posts: 2
[SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
Hello, I have installed Arch Linux on Lenovo ThinkPad T14 Gen 4 with WD Blue SN580 1TB NVME drive. (I decided to post here instead of to laptop issues, because I think this is more general kernel / hardware issue.) When I bought the laptop, I changed native sector size of the NVME from 512 bytes (factory default) to 4096 bytes and sanitized the NVME. At the time of installation I used Arch Linux 6.7.x, now Arch Linux 6.8.1. The NVME has 2 partitions: one FAT32 and one LUKS container with BTRFS filesystem with 3 subvolumes. Every now and then, during boot, I encounter the following error:
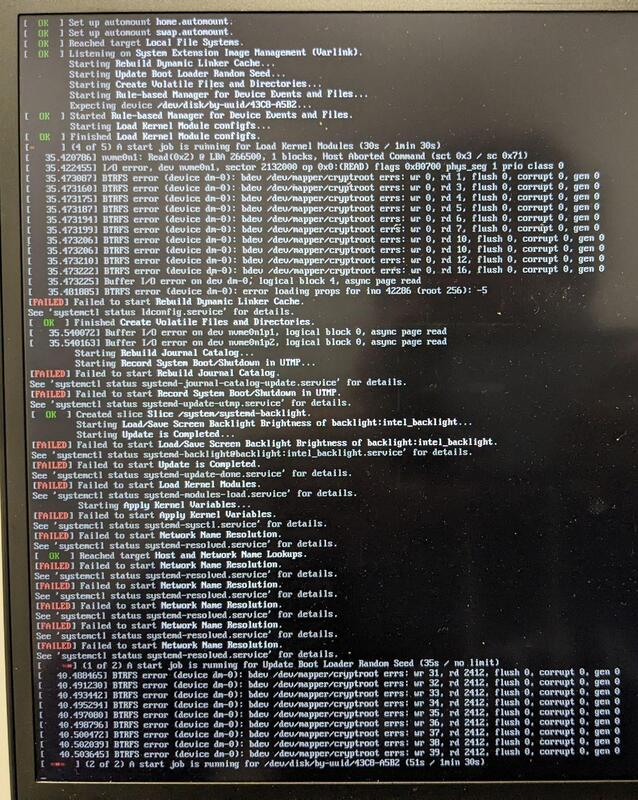
The same issue, captured different day:
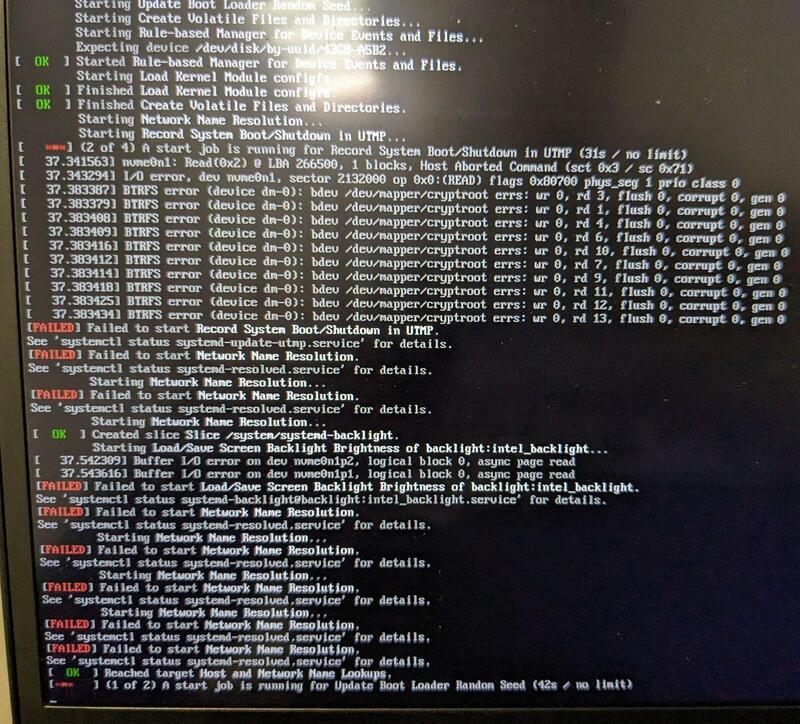
This problem was occasionally happening from the beginning, even on a freshly installed OS. When this error occurs, the system fails to boot. It's not possible to reboot it through Ctrl+Alt+Delete, I must only forcibly shut the laptop down via power button. I even tried to re-sanitize the NVME, reformat it and install Arch Linux from scratch, but the issue still occurs. When this error does not occur, the system boots just fine. Other than this issue, I am not seeing any issues with the NVME drive on day to day basis.
SMART self-tests don't report any errors. smartctl --log=selftest /dev/nvme0:
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.8.1-arch1-1] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF SMART DATA SECTION ===
Self-test Log (NVMe Log 0x06)
Self-test status: No self-test in progress
Num Test_Description Status Power_on_Hours Failing_LBA NSID Seg SCT Code
0 Extended Completed without error 7 - - - - -
1 Short Completed without error 7 - - - - -Kernel command line parameters for mounting the root FS:
rd.systemd.gpt_auto=0 rd.luks.name=7b55554b-68a0-4472-8445-1a39375cfd1b=cryptroot rd.luks.options=discard,no-read-workqueue,no-write-workqueue,password-echo=no,tpm2-device=auto root=/dev/mapper/cryptroot rootfstype=btrfs rootflags=defaults,rw,noatime,subvol=@,commit=60,compress=zstd:1,space_cache=v2 rootwaitContents of fstab:
UUID=43C8-A5B2 /boot/efi vfat defaults,noatime,fmask=0022,dmask=0022,codepage=437,iocharset=ascii,shortname=mixed,utf8,errors=remount-ro,x-systemd.automount 0 2
UUID=d587a045-3030-4417-9e0b-73179c751492 /home btrfs defaults,noatime,compress=zstd:1,space_cache=v2,subvol=@home,x-systemd.automount 0 0
UUID=d587a045-3030-4417-9e0b-73179c751492 /swap btrfs defaults,noatime,compress=no,space_cache=v2,subvol=@swap,x-systemd.automount 0 0
/swap/swapfile none swap defaults,noatime,nodev,noexec,nosuid,x-systemd.automount 0 0What I tried:
- Booting with intel_iommu=off command line parameter.
- Booting with pcie_aspm=off command line parameter.
- Booting with nvme_core.default_ps_max_latency_us=0 command line parameter.
- Booting with rootwait rootdelay=5 command line parameter.
However none if this helped. I am running out of ideas what is causing this problem, please do you have some idea what could be the issue?
Thank you very much for any ideas and have a nice day.
Last edited by armandleg (2024-04-04 22:17:00)
Offline
#2 2024-03-24 05:12:24
- undriven
- Member
- Registered: 2024-03-24
- Posts: 7
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
Given that the LBA/sector numbers are identical (266500 and 2132000) on different days, that's probably hardware failure.
Check for logged PCIe errors with dmesg or journalctl. You could try starting over with the drive in 512e mode, see if if changes anything.
Offline
#3 2024-03-24 09:29:05
- seth
- Member

- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,935
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
https://wiki.archlinux.org/title/Badblocks
Though, have all/both installations been luks+btrfs?
Tried "iommu=soft"?
memtest86+?
The device temperature is fine?
Any pattern to the failure (ie. "fails on reboots after the system was compiilnig stuff fo 5h, but is usually fine in the next morning. I live in the arctic, btw")?
Offline
#4 2024-03-24 18:27:08
- armandleg
- Member
- Registered: 2024-03-22
- Posts: 2
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
Yes, both installations were LUKS+BTRFS. Tried also iommu=soft, didn't help. Device temperature was fine, always in cca 30 - 45 celsius range. No pattern to the failure. Yesterday I tried to replace the NVME with Samsung NVME. Installed system with the same configuration. Since then I haven't encountered any such issues. Seems like either 1. the original NVME was faulty 2. maybe wasn't somehow compatible with Linux 3. didn't work properly in sector size = 4096 mode. When I'll have more time I'll try to play around with the original NVME a bit more, but for the time being the replacement solved the issue. Thank you very much for your assistance.
Offline
#5 2025-04-27 11:30:57
- ppp7032
- Member
- Registered: 2025-04-27
- Posts: 3
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
This is the only other instance I could find on the internet of someone with the exact same issue as me. Googling those BTRFS error messages got me ~4 irrelevant results.
I have a WD_BLACK SN770 1TB whose sector size I also changed from 512n to 4Kn. The drive clearly reported it supported this configuration, and the "nvme format" seemed to work. I then (coincidentally?) created the same configuration as you: GPT partitioning with an EFI system partition and a single LUKS-encrypted BTRFS. FAT32, LUKS, and BTRFS were all using 4K sector sizes and all appeared to be going well until I experienced this issue on first reboot. I found rebuilding my UKI via chroot would sometimes help me boot but after spending enough time booted (a few hours?), my PC would suddenly hang (browser stopped working, CTRL+Fx led to a black screen, I couldn't return back to the GUI from there and caps lock light stopped working - does that mean kernel panic?). "btrfs check" and "btrfs scrub" did not find any issues with the filesystem. Also, it wasn't just BTRFS that was failing here, the EFI system partition was also failing to mount on startup. Weirdly, I never had trouble mounting manually. Making this post now on a new install with the SSD back to 512n. This time, FAT32 and LUKS are using 512B sectors while BTRFS is using 4K sectors (BTRFS always defaults to 4K sectors regardless of logical sector size). Have not experienced the issue since changing back to 512n. Install was done using kernel 6.14.4-zen1-1-zen.
It seems some drives (potentially WD consumer drives in particular?) do not work well with 4Kn sectors despite reporting it as a valid configuration.
Last edited by ppp7032 (2025-04-27 11:31:55)
Offline
#6 2025-04-27 14:19:20
- ppp7032
- Member
- Registered: 2025-04-27
- Posts: 3
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
Alas! I've found someone else document the same issue here: https://halestrom.net/darksleep/blog/054_nvme/.
This person identified that their NVMe controller would lock up under heavy random read loads. OP and I were actually lucky to be using LUKS because I'm pretty sure using it in general (e.g. booting from it) inherently causes heavy random reads. This caused the issue, which would have been there regardless, to identify itself immediately.
3 people with the issue found so far and all 3 were using a Western Digital Color NVMe SSD... Hmm...
I've updated my drive's firmware and will (eventually) check if that fixed the issue for me, but I'm sceptical it'll help because apparently WD doesn't "believe" in firmware updates for consumer drives.
Edit: Firmware update does not fix the issue...
I'll be sticking to 512 for the foreseeable future on this drive.
Last edited by ppp7032 (2025-04-27 16:15:47)
Offline
#7 2025-05-07 18:19:36
- markasoftware
- Member
- Registered: 2014-06-22
- Posts: 17
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
I /think/ I am experiencing the same issue, but on somewhat different hardware!
I have a T14 gen 2 AMD with an Inland TN470 2TB SSD (Phison E27T controller). I sometimes get these I/O errors when booting right after entering my LUKS password as well and I generally have to hard reboot. I also think it sometimes is happening when my computer is waking up from sleep, because occasionally when waking from sleep the thinkpad light turns solid red (meaning the computer is awake) but the computer is completely unresponsive with no display or anything whatsoever, which I think could reasonably be caused by the SSD locking up (nobody else reports issues waking from sleep on this laptop on modern kernels). I'm using 512 byte sectors (didn't mess with the sector sizes).
I'm on NixOS with LUKS + EXT4.
Offline
#8 2025-05-07 20:26:54
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,935
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
Systematic STR+nvme issues are documented and addressed in https://wiki.archlinux.org/title/Solid_ … leshooting (disable APST, ASPM and the IOMMU, see whether that sabilizes the system, then look for the curcial parameter)
Offline
#9 2025-08-28 22:11:36
- wooptoo
- Member
- Registered: 2007-04-23
- Posts: 81
- Website
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
I found this topic linked from the wiki; apologies for reopening but wanted to share my findings.
On my WD_BLACK SN770 2TB I've been seeing the following errors on every single boot for months:
kernel: nvme 0000:01:00.0: platform quirk: setting simple suspend
kernel: nvme nvme0: pci function 0000:01:00.0
kernel: nvme 0000:01:00.0: PCIe Bus Error: severity=Correctable, type=Physical Layer, (Receiver ID)
kernel: nvme 0000:01:00.0: device [15b7:5017] error status/mask=00000001/0000e000
kernel: nvme 0000:01:00.0: [ 0] RxErr (First)
kernel: nvme nvme0: allocated 32 MiB host memory buffer (8 segments).
kernel: nvme nvme0: 12/0/0 default/read/poll queuesBut they stopped completely after I upgraded the firmware from:
Firmware Version: 731030WD
Firmware Version: 731130WDI don't think this is a coincidence at all.
The drive was configured with 512B sectors from the factory and that's how it stayed for years.
I've very recently switched to 4Kn sectors and have not been seeing any instability so far. I think i got lucky in the sense that i upgraded the firmware before the switch. I'll keep the 4Kn for now and monitor the drive for a bit.
Edit:
I dug a bit deeper into this. It seems to happen to DRAM-less / HMB SSDs like the SN550, SN580, SN770, etc.
- https://github.com/openzfs/zfs/discussions/14793
- https://www.spinics.net/lists/kernel/msg4372632.html
- https://community.frame.work/t/western- … oard/20616
Last edited by wooptoo (2025-08-29 00:37:31)
Offline
#10 2025-09-20 19:37:37
- ppp7032
- Member
- Registered: 2025-04-27
- Posts: 3
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
When I tested updating the firmware and found it to not fix my issue, the latest firmware was 731120WD rather than 731130WD. While this may seem promising, I remain skeptical because I cannot find this PCIe bus error in my kernel logs. I can only assume whatever problem that was was a bug in the older firmware that I too used to use.
This is, of course, assuming the PCIe bus error is even related. If it isn't, then things might actually look good.
As I no longer use LUKS, I'm not sure there's much of a point in myself retesting the issue. I never tried to reproduce the issue outside of LUKS so any test I do wouldn't be apples-to-apples anymore.
Offline
#11 2025-09-22 22:07:20
- wooptoo
- Member
- Registered: 2007-04-23
- Posts: 81
- Website
Re: [SOLVED] Machine sometimes fails to boot: Error: nvme0n1: Read(0x2)...
To update on this, I found the SN770 unusable with a 4K sector size, the controller errors out/times out constantly.
However the WD SN850X works perfectly fine, which was also confirmed by other from the ZFS thread on Github:
https://github.com/openzfs/zfs/discussions/14793
The following command crashes the SN770 controller on 4Kn:
fio --name=test --filename=/mnt/2/fio --size=1g --direct=1 --rw=read --ioengine=libaio --numjobs=2 --group_reportingOffline