You are not logged in.
- Topics: Active | Unanswered
#1 2025-06-06 07:46:24
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
[Solved]Can't boot system all services fail no journal also[solved]
I can't boot see those error don't know what to do just did a update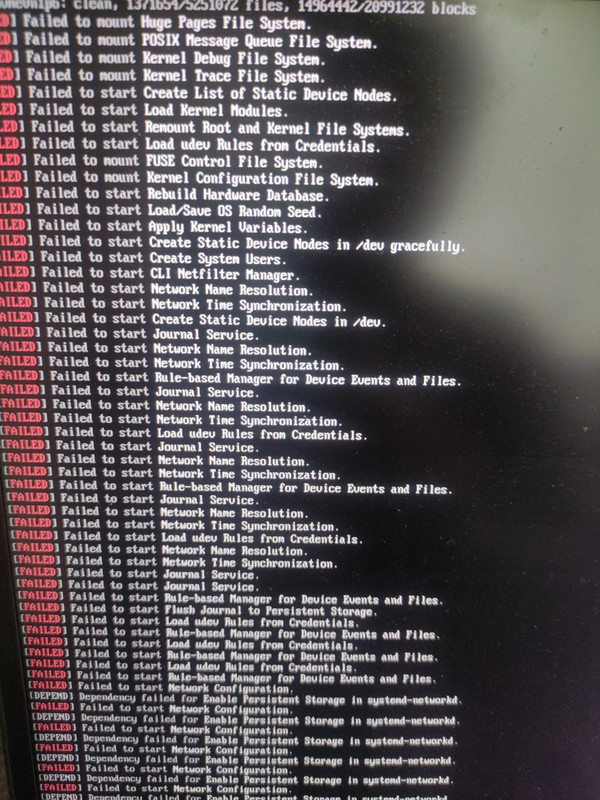
Last edited by mojtabazn (2025-06-08 01:07:19)
Offline
#2 2025-06-06 16:46:34
- airbus777neo
- Member
- Registered: 2025-06-03
- Posts: 38
Re: [Solved]Can't boot system all services fail no journal also[solved]
Hi,
I'd like to imagine that a fresh reinstall and re-writing over all of that would probably be the way to go, though I'm not sure how far into the installation you got...
Could you perhaps give any details on what you did during the installation? (although tbf it looks like, from how old your account is, you'd have much more experience than me)
Other than that I/anyone else have/has very little information to go off of for now...
Just a computer fanatic finally beginning to etch out of his shell in experience
"The man who chases two rabbits catches none." — Confucius
Offline
#3 2025-06-06 17:01:08
- airbus777neo
- Member
- Registered: 2025-06-03
- Posts: 38
Re: [Solved]Can't boot system all services fail no journal also[solved]
If you do believe you installed correctly, however, the most prominent issue I can imagine would be the case is hardware.
In order to check the disk health then you would have to insert a USB bootable medium, and then from there run
smartctl -a /dev/sda <replace sda with your disk name>And then inspect the results from therein
(It feels awful to so confidently command whom I can assume is an arch veteran...)
Just a computer fanatic finally beginning to etch out of his shell in experience
"The man who chases two rabbits catches none." — Confucius
Offline
#4 2025-06-06 18:41:24
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
Thanks bro I never face this kind of error before always I could find solution for my problem but at this I don't have any clues I did juts an upgrade I think this may related to groups or user don't know by the way smart say its fine everything on my drive
Offline
#5 2025-06-06 19:33:19
- seth
- Member

- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
by the way smart say its fine everything on my drive
While I don't really think that this is a broken disk, please don't paraphrase, https://bbs.archlinux.org/viewtopic.php?id=57855
Fwwi, the "overall health status: passed" and an empty bag have about the value of the bag (ie. that line is meaningless)
don't know what to do just did a update
Do you get a rescue shell?
What's the output of "uname -a"?
The main issue is likely the failure to mount the HPFS (do you use that as your root partition??) and the most common cause is to boot a different kernel than installed, failing to load any on disk modules for the booting kernel.
The usual cause for that is to forget or fail to mount the /boot partition before installing the kernel.
In that case, boot the install iso, make sure everything is properly mounted into place, chroot into the system and re-install the kernel.
Offline
#6 2025-06-06 23:00:02
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
Do you get a rescue shell?
No
What's the output of "uname -a"?
Dont Have shell to perform
The main issue is likely the failure to mount the HPFS (do you use that as your root partition??) and the most common cause is to boot a different kernel than installed, failing to load any on disk modules for the booting kernel.
The usual cause for that is to forget or fail to mount the /boot partition before installing the kernel.
i'm sure did correct before installing kernel i was on arch did upgrade and kernel installed
In that case, boot the install iso, make sure everything is properly mounted into place, chroot into the system and re-install the kernel.
I Did. mount root and boot reinstalled kernel but same error like image on First post
Offline
#7 2025-06-07 06:34:29
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
From the install iso:
lsblk -f | curl -F 'file=@-' 0x0.stthen make sure you've internet and arch-chroot into the installed system w/ the boot partition mounted into place
(df -h; cat /etc/fstab; pacman -Qs kernel; file /boot/vmlinuz-*; ls -l /boot) | curl -F 'file=@-' 0x0.st
journalctl -b -1| curl -F 'file=@-' 0x0.st
LC_ALL=C pacman -Qkk 2>&1 | grep -v ', 0 altered files' | grep -v backup > /tmp/howbadisit.txt
cat /tmp/howbadisit.txt | curl -F 'file=@-' 0x0.stOffline
#8 2025-06-07 07:36:11
- airbus777neo
- Member
- Registered: 2025-06-03
- Posts: 38
Re: [Solved]Can't boot system all services fail no journal also[solved]
While I don't really think that this is a broken disk, please don't paraphrase, https://bbs.archlinux.org/viewtopic.php?id=57855
Sorry, My bad...
Suppose I should've just left it as the install problem, and asked for more info. I was gonna mention something about issues mounting or the fstab (excuses), but...
At the end of the day I have loads to learn (since I literally got arch 2 weeks ago)
Just a computer fanatic finally beginning to etch out of his shell in experience
"The man who chases two rabbits catches none." — Confucius
Offline
#9 2025-06-07 07:49:52
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
Sorry, My bad...
No, why?
In the end it could still be all down to the disk falling apart - the request to not paraphrase was for the OP, specifically w/ the assertion that "smart say its fine everything on my drive", cause that's typically a misreading (because of the misleading overall health assessment)
Rule of thumb: ebkac >> bug >> hardware defect (except if a cable is involved, then it's: "cable >>>>> ebkac >> bug >> hardware defect" ![]() )
)
Offline
#10 2025-06-07 08:00:24
- airbus777neo
- Member
- Registered: 2025-06-03
- Posts: 38
Re: [Solved]Can't boot system all services fail no journal also[solved]
ohhh ok.
Thanks ![]()
Just a computer fanatic finally beginning to etch out of his shell in experience
"The man who chases two rabbits catches none." — Confucius
Offline
#11 2025-06-07 08:22:48
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
From the install iso:
lsblk -f | curl -F 'file=@-' 0x0.stthen make sure you've internet and arch-chroot into the installed system w/ the boot partition mounted into place
(df -h; cat /etc/fstab; pacman -Qs kernel; file /boot/vmlinuz-*; ls -l /boot) | curl -F 'file=@-' 0x0.st journalctl -b -1| curl -F 'file=@-' 0x0.st LC_ALL=C pacman -Qkk 2>&1 | grep -v ', 0 altered files' | grep -v backup > /tmp/howbadisit.txt cat /tmp/howbadisit.txt | curl -F 'file=@-' 0x0.st
http://0x0.st/8gpI.txt
http://0x0.st/8gpl.txt
http://0x0.st/8gpU.txt
also smart data
smartctl 7.5 2025-04-30 r5714 [x86_64-linux-6.14.8-1.1-cachyos] (local build)
Copyright (C) 2002-25, Bruce Allen, Christian Franke, [url=http://www.smartmontools.org]www.smartmontools.org[/url]
=== START OF INFORMATION SECTION ===
Model Number: SAMSUNG MZVL2512HCJQ-00B00
Serial Number: S675NX2T113677
Firmware Version: GXA7601Q
PCI Vendor/Subsystem ID: 0x144d
IEEE OUI Identifier: 0x002538
Total NVM Capacity: 512,110,190,592 [512 GB]
Unallocated NVM Capacity: 0
Controller ID: 6
NVMe Version: 1.3
Number of Namespaces: 1
Namespace 1 Size/Capacity: 512,110,190,592 [512 GB]
Namespace 1 Utilization: 413,281,607,680 [413 GB]
Namespace 1 Formatted LBA Size: 512
Namespace 1 IEEE EUI-64: 002538 b121c6f6cd
Local Time is: Sat Jun 7 08:24:13 2025 UTC
Firmware Updates (0x16): 3 Slots, no Reset required
Optional Admin Commands (0x0017): Security Format Frmw_DL Self_Test
Optional NVM Commands (0x0057): Comp Wr_Unc DS_Mngmt Sav/Sel_Feat Timestmp
Log Page Attributes (0x0e): Cmd_Eff_Lg Ext_Get_Lg Telmtry_Lg
Maximum Data Transfer Size: 128 Pages
Warning Comp. Temp. Threshold: 81 Celsius
Critical Comp. Temp. Threshold: 85 Celsius
Supported Power States
St Op Max Active Idle RL RT WL WT Ent_Lat Ex_Lat
0 + 8.37W - - 0 0 0 0 0 0
1 + 8.37W - - 1 1 1 1 0 200
2 + 8.37W - - 2 2 2 2 0 200
3 - 0.0500W - - 3 3 3 3 2000 1200
4 - 0.0050W - - 4 4 4 4 500 9500
Supported LBA Sizes (NSID 0x1)
Id Fmt Data Metadt Rel_Perf
0 + 512 0 0
=== START OF SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
SMART/Health Information (NVMe Log 0x02, NSID 0xffffffff)
Critical Warning: 0x00
Temperature: 33 Celsius
Available Spare: 100%
Available Spare Threshold: 10%
Percentage Used: 2%
Data Units Read: 51,210,515 [26.2 TB]
Data Units Written: 29,238,568 [14.9 TB]
Host Read Commands: 521,783,604
Host Write Commands: 473,333,361
Controller Busy Time: 2,960
Power Cycles: 803
Power On Hours: 3,696
Unsafe Shutdowns: 74
Media and Data Integrity Errors: 0
Error Information Log Entries: 0
Warning Comp. Temperature Time: 0
Critical Comp. Temperature Time: 0
Temperature Sensor 1: 33 Celsius
Temperature Sensor 2: 34 Celsius
Error Information (NVMe Log 0x01, 16 of 64 entries)
No Errors Logged
Self-test Log (NVMe Log 0x06, NSID 0xffffffff)
Self-test status: No self-test in progress
No Self-tests LoggedFSTAB :
# /dev/nvme0n1p6
UUID=de4fcf4b-dbb7-4a5a-8d90-7d1461bc5924 / ext4 rw,relatime 0 1
# /dev/nvme0n1p1 LABEL=SYSTEM
UUID=D248-472D /boot vfat rw,relatime,fmask=0022,dmask=0022,codepage=437,iocharset=ascii,shortname=mixed,utf8,errors=remount-ro 0 2Last edited by mojtabazn (2025-06-07 09:14:40)
Offline
#12 2025-06-07 09:05:32
- SimonJ
- Member

- From: Spain
- Registered: 2021-05-11
- Posts: 335
- Website
Re: [Solved]Can't boot system all services fail no journal also[solved]
Is this Arch or Cachyos? If the latter you would need to ask here https://discuss.cachyos.org/
Rlu: 222126
Offline
#13 2025-06-07 09:07:49
- airbus777neo
- Member
- Registered: 2025-06-03
- Posts: 38
Re: [Solved]Can't boot system all services fail no journal also[solved]
yeah I did notice that...
x86_64-linux-6.14.8-1.1-cachyos wrote:Last edited by airbus777neo (2025-06-07 17:15:49)
Just a computer fanatic finally beginning to etch out of his shell in experience
"The man who chases two rabbits catches none." — Confucius
Offline
#14 2025-06-07 09:10:40
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
Please use [code][/code] tags, not "quote" tags. Edit your post in this regard.
warning: grub: /etc/grub.d/10_linux (No such file or directory)
warning: grub: /etc/grub.d/20_linux_xen (No such file or directory)
warning: grub: /etc/grub.d/25_bli (No such file or directory)
warning: grub: /etc/grub.d/30_os-prober (No such file or directory)
warning: grub: /etc/grub.d/30_uefi-firmware (No such file or directory)
warning: grub: /etc/grub.d/40_custom (No such file or directory)
warning: grub: /etc/grub.d/41_custom (No such file or directory)Why?
So is this cachyos, or blackarch, or a frankenstein collection of repos?
The last successful boot was on the - not updated - 6.13 cachyos kernel, which one are you trying to boot right now?
Does the other kernel boot?
Does the fallback image?
Edit: +b and also F5.
Last edited by seth (2025-06-07 09:11:49)
Offline
#15 2025-06-07 09:19:12
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
no its arch just have some cachyos packages i have one cachyos kernel and official arch before update both was working after update both don't work even with fallback
Offline
#16 2025-06-07 12:46:03
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
Ok, remove the "quiet" from the boot parameters, instead add "sysrq_always_enabled=1 systemd.unit=rescue.target"
See what of the failing boot you can preserve, ideally, if the root partition (which is just ext4) gets mounted, rebooting w/ the magic sysrq (the print key is usually the sysrq) and the entire alt+sysrq+r,e,i,s,u,b (give it a second between each shortcut) you can properly reboot and preserve the journal of the boot.
Offline
#17 2025-06-07 13:41:44
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
Ok, remove the "quiet" from the boot parameters, instead add "sysrq_always_enabled=1 systemd.unit=rescue.target"
See what of the failing boot you can preserve, ideally, if the root partition (which is just ext4) gets mounted, rebooting w/ the magic sysrq (the print key is usually the sysrq) and the entire alt+sysrq+r,e,i,s,u,b (give it a second between each shortcut) you can properly reboot and preserve the journal of the boot.
I fixed that by overwrite shadow package don't know why it was bugged now system load but have problem with desktop
Xorg works just by startx
Starting kde on Wayland black screen with courser
Starting kde on xorg give black screen with courser
Start sddm give black screen with courser
Offline
#18 2025-06-07 13:46:14
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
shadow lacked a bunch of manpages and I missed
warning: shadow: /usr/bin/groupmems (Permissions mismatch)
warning: shadow: /usr/bin/groups (Modification time mismatch)
warning: shadow: /usr/bin/groups (Size mismatch)
warning: shadow: /usr/bin/groups (SHA256 checksum mismatch)For the updated situation, please post your complete system journal for the boot:
sudo journalctl -b | curl -F 'file=@-' 0x0.stOffline
#19 2025-06-07 14:07:52
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
shadow lacked a bunch of manpages and I missed
warning: shadow: /usr/bin/groupmems (Permissions mismatch) warning: shadow: /usr/bin/groups (Modification time mismatch) warning: shadow: /usr/bin/groups (Size mismatch) warning: shadow: /usr/bin/groups (SHA256 checksum mismatch)For the updated situation, please post your complete system journal for the boot:
sudo journalctl -b | curl -F 'file=@-' 0x0.st
Here sir
Last edited by mojtabazn (2025-06-07 14:17:09)
Offline
#20 2025-06-07 14:14:49
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
I suspect https://0x0.st/8gO7.txt ?
Jun 07 17:34:40 bl-ck0ut kernel: i915 0000:00:02.0: Direct firmware load for edid/edid.bin failed with error -2
Jun 07 17:34:40 bl-ck0ut kernel: i915 0000:00:02.0: [drm] *ERROR* [CONNECTOR:241:eDP-2] Requesting EDID firmware "edid/edid.bin" failed (err=-2)
…
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: Direct firmware load for edid/edid.bin failed with error -2
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: [drm] *ERROR* [CONNECTOR:127:HDMI-A-1] Requesting EDID firmware "edid/edid.bin" failed (err=-2)
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: Direct firmware load for edid/edid.bin failed with error -2
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: [drm] *ERROR* [CONNECTOR:130:eDP-1] Requesting EDID firmware "edid/edid.bin" failed (err=-2)
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: Direct firmware load for edid/edid.bin failed with error -2
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: [drm] *ERROR* [CONNECTOR:133:DP-1] Requesting EDID firmware "edid/edid.bin" failed (err=-2)
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: Direct firmware load for edid/edid.bin failed with error -2
Jun 07 17:34:40 bl-ck0ut kernel: nvidia 0000:01:00.0: [drm] *ERROR* [CONNECTOR:133:DP-1] Requesting EDID firmware "edid/edid.bin" failed (err=-2)
…
Jun 07 17:34:40 bl-ck0ut kernel: NVRM: loading NVIDIA UNIX Open Kernel Module for x86_64 575.57.08 Release Build (root@)
Jun 07 17:34:40 bl-ck0ut kernel: NVRM: testIfDsmSubFunctionEnabled: GPS ACPI DSM called before _acpiDsmSupportedFuncCacheInit subfunction = 11.
Jun 07 17:34:40 bl-ck0ut kernel: NVRM: testIfDsmSubFunctionEnabled: GPS ACPI DSM called before _acpiDsmSupportedFuncCacheInit subfunction = 11.That aside, there seems no effort to start SDDM or plasma?
Offline
#21 2025-06-07 14:20:45
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
Offline
#22 2025-06-07 14:24:03
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
Start sddm
http://0x0.st/8gVq.txt
Last edited by mojtabazn (2025-06-07 14:26:45)
Offline
#23 2025-06-07 14:28:40
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
…
Jun 07 15:54:26 bl-ck0ut kwin_x11[5233]: Could not initialize GLX
…Please post your Xorg log, https://wiki.archlinux.org/title/Xorg#General
Offline
#24 2025-06-07 14:50:23
- mojtabazn
- Member
- Registered: 2013-10-20
- Posts: 65
Re: [Solved]Can't boot system all services fail no journal also[solved]
Offline
#25 2025-06-07 15:01:14
- seth
- Member
- From: Won't reply 2 private help req
- Registered: 2012-09-03
- Posts: 76,337
Re: [Solved]Can't boot system all services fail no journal also[solved]
[ 811.713] (II) modeset(0): EDID vendor "TMX", prod id 5633
[ 808.591] (II) NVIDIA(G0): Setting mode "NULL"
[ 808.616] (II) AIGLX: Screen 0 is not DRI2 capable
[ 808.639] (II) IGLX: Loaded and initialized swrast
[ 808.639] (II) GLX: Initialized DRISWRAST GL provider for screen 0There's an output on the intel chip, nvidia works for prime offloading - and you somehow end up w/ the software rasterizer.
pacman -Qikk mesa xorg-server nvidia-utilsOffline